
Artificial intelligence is a major component in manufacturing transformation projects, but using the technology to invent new digital capabilities that will create competitive advantages requires a disciplined use case approach. By Jomit Vaghela
Until now, organizations have looked to technology companies like Microsoft to provide digital tools for improving efficiency, increasing productivity, and driving innovation. Now, the organizations achieving the greatest success are applying these tools and technologies to invent their own digital solutions to solve complex business and societal issues. In the process, they’re essentially becoming technology companies themselves as they drive progress and innovation in their industries. We refer to this approach as “tech intensity,” and we strongly believe it is what will determine an organization’s future success.
According to our State of Tech Intensity 2019 Study, the vast majority of business and technology leaders surveyed believe that tech intensity is a key competitive driver, and there’s widespread agreement that tech intensity — defined as the applied use of a creative, entrepreneurial mindset to invent new digital capabilities using advanced technologies such as artificial intelligence (AI) and the Internet of Things (IoT) and symbolized in this formula: Tech Intensity = (Tech adoption x Tech capability) ^ Trust — will have a significant impact on global communities and organizational culture.
In this article, I will share some challenges and best practices for achieving tech intensity in AI, which is one of the most hyped technology areas in manufacturing. Every transformation initiative seen today includes an AI component in it. Whether its improving operational efficiency or improving productivity or reducing operational cost, AI and machine learning is the core component for all these initiatives. In fact, a lot of times, AI adoption is the core strategy that is driving these initiatives.
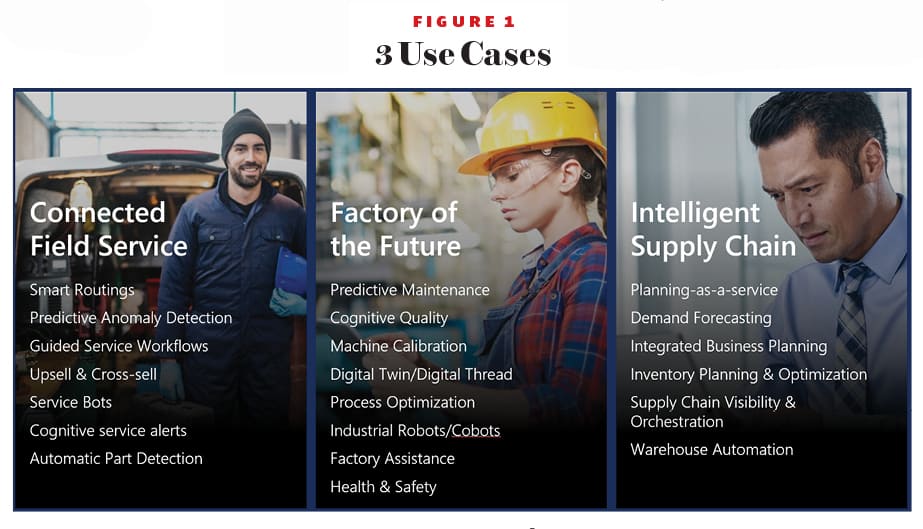
The fourth dilemma in the AI journey is to decide which of the three uses cases discussed below to start with.There are many case studies on how AI produced great results for others, but every manufacturing company is different. A common best practice is to start with a use case that gives you the best ROI but execute on the ones that have enough data.

“When choosing how to start investing in AI, it is important to consider the organization’s AI maturity and the potential ROI of any investment.”
So how do you know if you have enough data and how do you start creating the model? This is the number one challenge.
Challenge 1: Skillsets
There are two main sets of skills needed to start your AI journey – domain expertise and machine learning.
Most manufacturers these days either have a data scientist or are trying to hire one. At the same time, they are working to upskill their existing team to learn new tools and techniques around machine learning. Given the broad impact of AI, this is happening pretty much across all industries, resulting in a huge gap between the supply and demand of these skills.
How can we solve this challenge?
One way manufacturers are solving this is by upskilling their existing domain experts. A key skill for a machine learning project is the ability to understand the data coming out of both the IT and OT systems. Most customers do have experts who understand their domains very well, but they lack the skills to apply these new machine learning techniques to better reason about the data.
If these domain experts are enabled with the right set of tools and techniques, they can amplify their skills and become citizen data scientists. One such tool is automated machine learning, which helps these domain experts generate the machine learning models from the data. It’s like machine learning for machine learning.
The most important input it requires is the right data. Which brings us to our second most important challenge.
Challenge 2: Data! Data! Data!
There are three main aspects of the data challenge in manufacturing. The first aspect is the sheer number of both IT and OT systems across the organization which store domain-specific data. Customer data, supply chain data, factory data, finance data, and connected product data are examples of domain-specific data being generated. Within these data silos are multiple instances of sub systems such as MES systems, SCADA systems, and ERP systems that are holding one piece of the data.
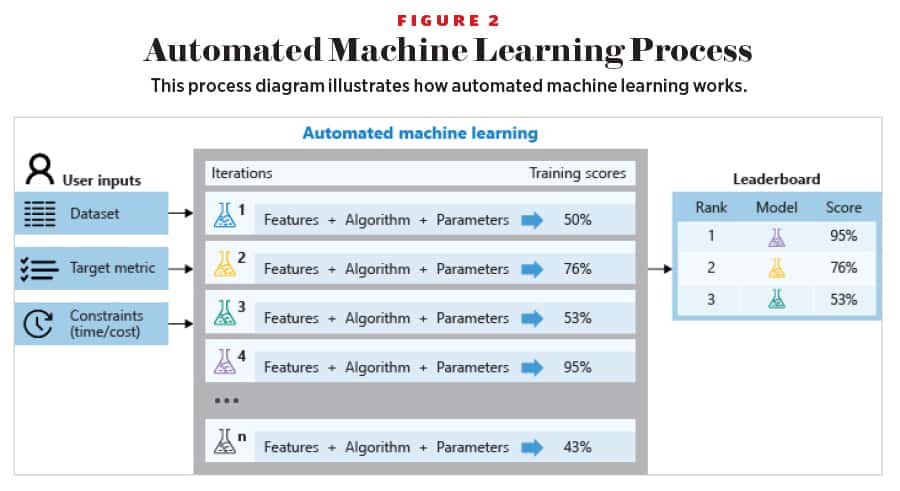
The second aspect is the enterprise’s needs around security, compliance, governance, discovery, and management of these data silos. And the third aspect is the AI requirements around identifying relevant data; what constitutes enough data, quality data, and training; and deploying and monitoring machine learning models at scale.
But many projects get stuck as a result of a failure to address these aspects of the data challenge. How can we solve these challenges?
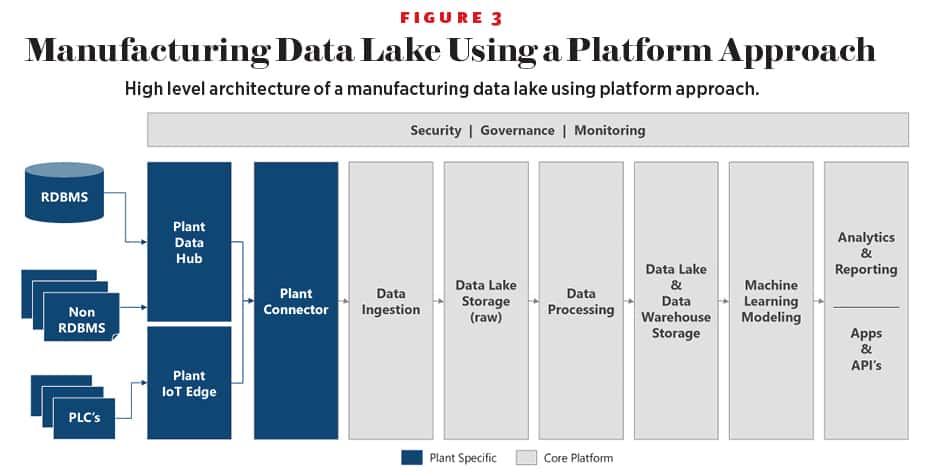
For data silos, one approach is to create a unified data lake-like environment, which allows data scientists, operational engineers, as well as machine learning engineers to access one common place for all their data needs. There are many architecture decisions that need to happen around this such as: should there be one big data lake which can be managed centrally or should a common data layer be created for each business unit to maintain its own domain-specific data lake? The answer, of course, depends on the use case, organizational structure, compliance needs, and many other factors.
The key is to start working in parallel on the data pipelines to connect both the OT systems as well as IT systems, as well as the machine learning pipelines, so that time to value can be accelerated for these initiatives. Some of the core tenants of data management to keep in mind while working on your data estate include minimizing data duplication and separating out storage and compute for reducing cost and risk while also modernizing data management by improving discovery and source of truth issues, creating agility using appropriate data access methods, reducing latency for analytics solutions, and including machine learning capabilities in analytics.
For enterprise and AI needs, the best solution is to use a platform approach. So instead of implementing use case-specific solutions for each business unit, build an AI platform which can enable every business unit to not only work on incremental, evolutionary use cases of today but also experimental, aspirational use cases of the future.
Should you start with a platform approach on day one? Absolutely not, but that should be the North Star. In most cases, we have seen parallel workstreams on both the use case-specific solutions while enabling the platform approach. Below is an example architecture of what some of these platforms can look like. The platform approach mindset can also help make better build versus buy decisions in the overhyped world of AI and Industrial IoT.
Once you decide on the right platform approach, which provides the right data at the right time, you will be ready for the next challenge in building and deploying AI models.
Challenge 3: Software Engineering for Machine Learning
Most IT and OT teams know how to build, deploy, and manage their assets and applications. They also know how to monitor them, troubleshoot them, and upgrade them. But do they know how to do the same things for machine learning models? How does one go about debugging and monitoring a machine learning model? A machine learnig study tried to answer these and many other questions by interviewing various roles involved in developing AI applications.
There are nine stages of a typical machine learning workflow:
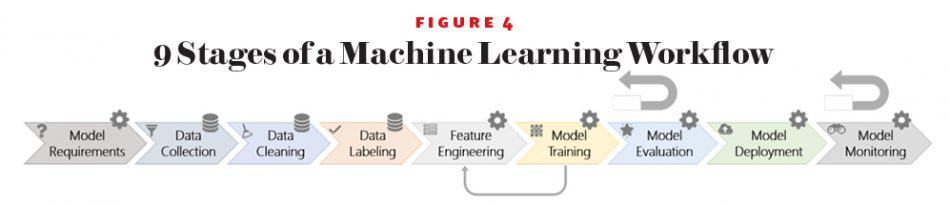
Some stages are data-oriented (e.g., collection, cleaning, and labeling) and others are model-oriented (e.g., model requirements, feature engineering, training, evaluation, deployment, and monitoring). There are many feedback loops in the workflow. The larger feedback arrows denote that model evaluation and monitoring may loop back to any of the previous stages. The smaller feedback arrow illustrates that model training may loop back to feature engineering (e.g., in representation learning).
The study identified some key differences in how software engineering has evolved for application domains and how it can be adapted to support AI applications and platforms. For example, a main component of a typical app is the code that ships with the software. But for machine learning, it is all about the data. Like code, a small change in data can cause major changes in the ML models. As a result, things like collecting, storing, and versioning data are very critical and very different from software engineering.
Another example is around reusability. Reusing existing code is easy but reusing a model across different domains is non-trivial. For each new domain, the model may require full re-training with a new dataset. And each dataset will require the same collecting and cleaning efforts so the amount of work may be the same as building a new model. There are techniques like transfer learning, but they only work in certain domains. In software engineering, you can create different independent modules and then integrate them via APIs to make an end-to-end system. But creating such modules in machine learning is very difficult. For example, if you have a general model to find anomalies and a model to find anomalies in credit transactions, you cannot just take these two models and expect them to work together.
Based on these learnings, the study summarizes key best practices with machine learning in software engineering like end-to-end pipeline support, data availability, collection, cleaning and management, model debugging and interpretability, model evolution, evaluation, and deployment and compliance. The AI platform needs to follow these best practices, while also delivering continuous value from machine learning models. This is where machine learning operations (MLOps), or DevOps for machine learning, can help.
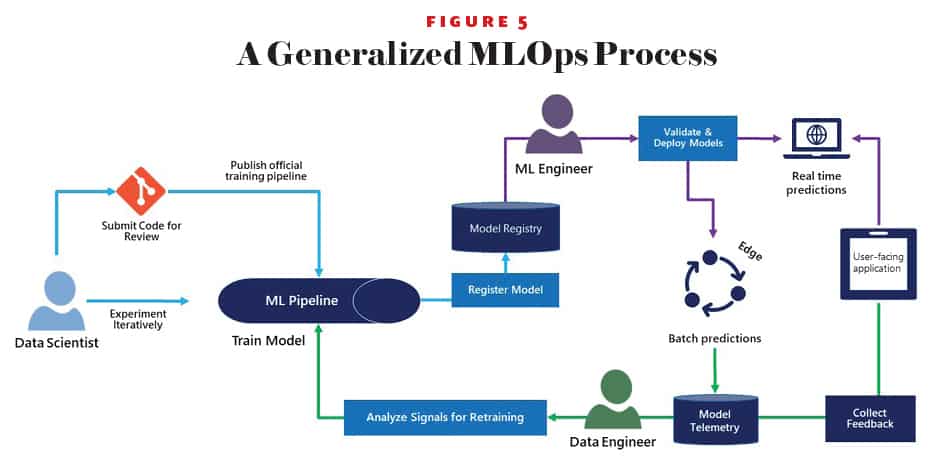
MLOps is based on DevOps principles and practices that increase the efficiency of workflows through continuous integration, delivery, and deployment. MLOps applies these principles to the machine learning process, with the goal of faster experimentation and development of models, faster deployment of models into production, and quality assurance.
Models differ from code because they have an organic shelf life and will deteriorate unless maintained. Once deployed, they can add real business value, and this gets easier when data scientists are given the tools to adopt standard engineering practices and MLOps enables data science and IT teams to collaborate and increase the pace of model development and deployment via monitoring, validation, and governance of machine learning models.
Final Challenge: AI Strategy
In spite of technology being where it is and data volumes being enormous, there is a gap between ambition and reality. According to a 2018 Boston Consulting Group AI global survey, on average there are only 16% of companies that have fully implemented more than one AI use case. This contrasts with more than 85% of companies saying they are planning to implement AI.
The challenge this contrast reveals is not the technology itself but the lack of a holistic strategy that enables transformation throughout the organization. Creating this strategy can be challenging because there are many parts of the organization. First, the strategy needs to incubate new ideas by identifying, testing, and scaling innovative opportunities. But it also needs to make sure the primary revenue streams remain healthy and grow. Finally, it needs to make sure cost centers such as marketing, manufacturing, and customer service are running as efficiently as possible.
This is more about culture and mindset than technology, and it is one of the most difficult challenges. Many organizations struggle with this. Business units often try to do their own thing around AI outside of the purview of IT to avoid friction. This results in yet another silo of information, data, and skillset. Sometimes this decentralization is very good for innovation, but it makes governance very hard. What’s needed is a balance. There are some successful approaches on how mature customers are trying to tackle this challenge.

“A key skill for a machine learning project is the ability to understand the data coming out of both the IT and OT systems.”
One such approach is to create a two-sided Center of Excellence (CoE) rooted in the business need to accelerate innovation. One side is the traditional CoE or a service center focused on self-sufficiency (evolutionary) aspects and the other side focused on accelerating and managing innovation (revolutionary) aspects.
AI has changed how information is used. This is far more than great reporting. It is now about embedding analytics and intelligence in workflows, streamlining production processes, and changing how people interact with a company. Hence, the focus on the evolutionary side of the CoE needs to accommodate skills in workflow and process improvement, as well as new roles such as data scientists and business liaisons to help make sure that the CoE is relevant to a new audience.
Along with this it also needs to empower businesses to innovate more quickly and must match the velocity and potential of change; therefore, the big questions are: how can an organization accelerate change, how can it be more nimble in order to experiment and innovate faster?
This model, often called an Innovation Factory, has two parts. Part one is an experimentation lab or garage where ideas can be acted on and tested quickly. Those that are successful can then be moved to production quickly and/or inserted into existing processes. Part two is a governance model to manage the portfolio of innovation projects. The process to go from ideation to incubation to scale must also be run as a business but needs rigor to help make sure that innovation adds value to the business versus simply being technology experiments.
Maximizing the Value of AI
AI transformation is a journey. When choosing how to start investing in AI, it is important to consider the organization’s AI maturity and the potential ROI of any investment. First, understand the organization’s skills and capabilities when it comes to AI. By understanding the organizational capabilities, one can define a well-suited strategy. This will start the organization on a cycle of AI maturity and value that will enable it to expand customer engagement, optimize operations, and develop new products and services never thought possible.
Next, start by focusing on where AI can drive the most value. With all the pressure on organizations to invest in AI, it is easy to get caught up in the flurry of possibilities and spread resources too thin by investing in too many applications at once. To help ensure one chooses the right use cases, work with the technical department to analyze which AI solutions suit your level of AI capabilities, could be easily implemented, and will have the biggest impact.
Ultimately, by choosing the right use cases and investing in the AI capabilities, technical departments, operational departments, and employees, you can grow the organization’s AI maturity and maximize the value it gains from AI. M